-
개발자를 위한 인덱스 생성과 SQL작성 노하우 : 18-20STUDY/DB 2022. 8. 15. 23:06
- 오라클 기능
1. FLASHBACK
오라클에서 삭제 혹은 갱신된 레코드는 commit 하기 전에는 rollback 명령어를 사용하면 원복이 가능했다. 만약 이미 commit 명령어가 실행돼 완전히 삭제 혹은 갱신됐다면, 지금까지는 레코드 원복이 불가능했지만, 오라클 10g 이후부터는 flashback 기능을 제공해 commit 이전 상태의 레코드도 조회할 수 있게 됐으며, 레코드 원복까지도 가능하다.
commit/rollback 여부와 상관없이 한시적으로 데이터를 백업하는 기능을 지원해, 특정 시점의 데이터를 원복 가능하게 됐는데, flashback 기능은 오라클 서버에 부하를 주므로 사전에 설정된 제한 시간만큼만 지원된다. db_flashback_retention_target 에서 설정된 시간을 확인할 수 있다.
SELECT * FROM V$PARAMETER WHERE NAME = 'db_flashback_retention_target'
조회된 value값은 분 단위 시간을 의미한다. 제한된 설정 시간 내에서 과거 시점의 데이터를 조회하거나 원복할 수 있다. 만약 사용 권한이 없다면 DBA에게 요청해 DBMS_FLASHBACK 패키지에 대한 EXECUTE 권한을 부여받아야 한다.
-- 1시간 전 시점의 고객 테이블을 조회하는 쿼리
SELECT * FROM 고객 AS OF TIMESTAMP (SYSTIMESTAMP - INTERVAL '1' HOUR)
-- 20분 전 시점의 고객 테이블을 조회하는 쿼리
SELECT * FROM 고객 AS OF TIMESTAMP (SYSTIMESTAMP - INTERVAL '20' MINUTE)
-- 2022년 01월 01일 00시 00분 시점의 고객 테이블을 조회하는 쿼리
SELECT * FROM 고객 AS OF TIMESTAMP TO_DATE('202201010000', 'YYYYMMDDHH24MI')
-- 30분 전 시점의 고객 테이블을 조회하는 쿼리
SELECT * FROM 고객 AS OF TIMESTAMP SYSDATE - 30 / (24 * 60)
-- 20분 전에서 10분 전 사이에 삭제된 레코드를 원복하는 쿼리
INSERT INTO 고객
SELECT * FROM 고객 AS OF TIMESTAMP (SYSTIMESTAMP - INTERVAL '20' MINUTE)
MINUS
SELECT * FROM 고객 AS OF TIMESTAMP (SYSTIMESTAMP - INTERVAL '10' MINUTE)
-- 특정 시점에 존재했던 레코드를 조회해 새로운 테이블을 생성,추가하는 쿼리
CREATE TABLE 고객_BACKUP
AS
SELECT * FROM 고객 AS OF TIMESTAMP TO_DATE('202201010000', 'YYYYMMDDHH24MI')2. 스케줄 작업
오라클에서 스케줄 작업을 하려면 SNP_PROCESS가 활성돼 있어야 한다. 만약 활성돼 있지 않다면 INIT.ORA 파일의 JOB_QUEUE_PROCESSES 파라미터를 수정하고 재구동한다.
스케줄 수행 시간 단위
- 1분 간격 : SYSDATE + 1 / 24 / 60
- 5분 간격 : SYSDATE + 5 / 24 / 60
- 1시간 간격 : SYSDATE + 1 / 24
- 매일 오전 1시에 실행 : TRUNC(SYSDATE) + 1 + 1 / 24
- 매일 오후 11시간에 실행 : TRUNC(SYSDATE) + 23 / 24
- 매월 첫번째 일요일 01시에 실행 : TRUNC(NEXT_DAY(LAST_DAY(SYSDATE), '일')) + 1 / 24
- 매월 마지막일 오후 11시에 실행 : TRUNC(LAST_DAY(SYSDATE)) + 23 / 24
예시
스케줄 생성
네트워크 트래픽을 집계하는 P_네트워크 프로시저가 이미 생성돼 있을 때 P_네트워크 프로시저를 5분 간격으로 스케줄 작업을 진행하려면, USER_JOBS 테이블에 네트워크 스케줄 작업을 생성(INSERT) 한다.(스케줄은 5분 간격으로 실행).
DECLARE
V_JOB_NO NUMBER; -- JOB_NO 1 : 네트워크 스케줄 JOB 번호
BEGIN
DBMS_JOB.SUBMIT(V_JOB_NO, 'P_네트워크;', SYSDATE, 'SYSDATE + 5 / 24 / 60');
END;조직 및 인사 정보를 동기화하는 P_동기화 프로시저가 이미 생성돼 있을 때, P_동기화 프로시저로 매일 오전 1시에 스케줄 작업을 진행하려면, USER_JOBS 테이블에 동기화 스케줄 작업을 생성(INSERT)한다. (스케줄은 매일 오전 1시에 실행).
DECLARE
V_JOB_NO NUMBER; -- JOB_NO 2 : 동기화 스케줄 JOB 번호
BEGIN
DBMS_JOB.SUBMIT(V_JOB_NO, 'P_동기화;', SYSDATE, 'TRUNC(SYSDATE) + 1 + 1 / 24');
END;스케줄 구동
EXECUTE DBMS_JOB.RUN(1) -- JOB_NO 1 : 네트워크 스케줄 실행
EXECUTE DBMS_JOB.RUN(2) -- JOB_NO 2 : 동기화 스케줄 실행스케줄 중단
EXECUTE DBMS_JOB.BROKEN(2, TRUE) -- JOB_NO 2 : 동기화 스케줄 중단
스케줄 삭제
EXECUTE DBMS_JOB.REMOVE(2) -- JOB_NO 2 : 동기화 스케줄 삭제
3. SAMPLE 혹은 SAMPLE BLOCK을 이용한 SAMPLE SCAN
테이블을 접근하는 방식에는 테이블을 직접 접근해 모든 블록을 읽는 풀스캔과 인덱스를 이용해 테이블에 접근하는 랜덤 액세스 방식이 있다. 오라클 8.1 이후부터 데이터를 접근할 때 샘플스캔 방식이 추가됐는데, 해당 방식을 이용하면 데이터를 랜덤하게 샘플링할 수 있다.
SELECT * FORM 고객 SAMPLE BLOCK(10) WHERE 지역 = '인제' ORDER BY 고객명
SAMPLE 구간에 사용 가능한 값은 0-100 사이다. 더 정확한 표현은 0.000001보다 크거나 같고 100보다 작아야 한다. 위 쿼리에서 SAMPLE BLOCK(10)은 블록 단위로 주어진 값의 비율만큼 읽어 오는 것을 의미한다.
SELECT * FORM 고객 SAMPLE(10) WHERE 지역 = '인제' ORDER BY 고객명
위 쿼리에서 SAMPLE(10)은 레코드 단위로 주어진 값의 비율만큼 읽어 오는 것을 의미한다. 일반적으로 실행계획에서 Cost값은 SAMPLE보다 SAMPLE BLOCK이 더 낮다. Get Block 값도 SAMPLE보다 SAMPLE BLOCK이 더 낮다. 비용 측면을 고려하면 SAMPLE BLOCK을 사용하는 것이 더 좋다.
규모가 작은 테이블보다 큰 테이블에서 더 정확한 샘플링을 할 수 있으며, 작은 테이블에서의 사용은 무의미할 수 있다. 대용량 테이블에서는
SELECT COUNT(*) * 100 FROM 고객 SAMPLE BLOCK(1)
쿼리로 레코드 수를 빠르게 확인할 수 있다. 1%를 샘플링해 구한 레코드 카운터 값에 곱하기 100을 했으므로 전체 레코드와 유사한 결과값을 얻을 수 있다. 같은 쿼리를 여러 번 실행해도 동일한 결과값을 리턴하지는 않고 유사한 값을 리턴하는 것을 명심해야 한다.
4. WM_CONCAT
문자열을 결합하는 CONCAT 함수는 문자열 결합 연산자 || 와 동일한 의미로,
SELECT CONCAT(컬럼1, 컬럼2) FROM 테이블
SELECT 컬럼1 || 컬럼2 FROM 테이블위 방식으로 사용된다.
WM_CONCAT은 종으로 된 컬럼 값을 횡으로 구현하는 기능을 갖는다.
번호1010 국가 도시 인구(단위 : 만) 1 한국 서울 1010 2 중국 베이징 1961 3 한국 부산 351 4 일본 도쿄 1329 5 한국 안동 16 쿼리
SELECT 국가, WM_CONCAT(도시) AS 도시들, SUM(인구) AS 총인구
FROM 도시인구현황
WHERE 인구 > 10
GROUP BY 국가
ORDER BY 총인구 DESC결과
국가 도시들 총 인구(단위: 만) 중국 베이징 1961 한국 서울, 부산, 안동 1377 일본 도쿄 1329 5. REGEXP_SUBSTR
문자열을 분리하는 SUBSTR 함수는
SELECT SUBSTR(주문일자, 1, 6) AS 주문년월 FROM 테이블
위 방식으로 사용된다.
REGEXP_SUBSTR 함수는 횡으로 된 값을 종으로 구현할 수 있다. 구분자 콤마(,)에 주의한다.
번호 이름 취미리스트 우수고객 1 심인술 축구,영화 Y 2 김윤호 자전거,낚시 N 3 김의석 여행,스키 Y 쿼리
SELECT 이름, REGEXP_SUBSTR(취미리스트, '[^,]+', 1, LEVEL) AS 취미
FROM 고객
WHERE 우수고객 = 'Y'
CONNECT BY REGEXP_SUBSTR(취미리스트, '[^,]+', 1, LEVEL) IS NOT NULL
GROUP BY 이름, 취미리스트, LEVEL
ORDER BY 이름, 취미결과
이름 취미 김의석 스키 김의석 여행 심인술 영화 심인술 축구 REGEXP_SUBSTR 함수는 횡을 종으로 구현하는 용도로도 사용되지만, 다음 예시처럼 문자열을 분리하는 용도로 더 많이 사용된다.
번호 이름 전화번호 주소 1 김상미 02-274-3328 서울 강동구 강일동 123번지 2 이도윤 02-272-2723 서울 강동구 강일동 272번지 3 허은미 02-392-8989 서울 서초구 우면동 237번지 쿼리
SELECT 이름
, REGEXP_SUBSTR(전화번호, '[^-]+', 1, 1) AS 지역
, REGEXP_SUBSTR(전화번호, '[^-]+', 1, 2) AS 국번
, REGEXP_SUBSTR(전화번호, '[^-]+', 1, 3) AS 전화번호
, REGEXP_SUBSTR(주소, '[^ ]+', 1, 1) AS 시도명
, REGEXP_SUBSTR(주소, '[^ ]+', 1, 2) AS 시군구명
, REGEXP_SUBSTR(주소, '[^ ]+', 1, 3) AS 읍면동명
FROM 고객결과
이름 지역 국번 전화번호 시도명 시군구명 읍면동명 김상미 02 274 3328 서울 강동구 강일동 이도윤 02 272 2723 서울 강동구 강일동 허은미 02 392 8989 서울 서초구 우면동 - 오라클 딕셔너리
DBMS를 관리하기 위한 정보를 갖고 있는 테이블의 집합을 딕셔너리(DICTIONARY)라 한다. 오라클은 딕셔너리를 통해 수많은 정보를 제공한다. 딕셔너리는 오라클 시스템에 대한 정보의 보고이며, 데이터 사전이라고 부르기도 한다.
-- 사용자 소유의 모든 오브젝트 정보 조회
SELECT * FROM USER_OBJECTS
-- 사용자 소유의 테이블 정보 조회
SELECT * FROM USER_TABLES
-- 현재 시점의 세션 정보 조회
SELECT * FROM V$SESSIONDB 시스템 정보를 제공하는 수많은 딕셔너리 조회
SELECT * FROM DICTIONARY 혹은 SELECT * FROM DICT

700여 개 이상의 시스템 정보를 제공하는데, 그 중 필요한 부분만 조회
SELECT * FROM DICTIONARY
WHERE TABLE_NAME LIKE '%INDEX%'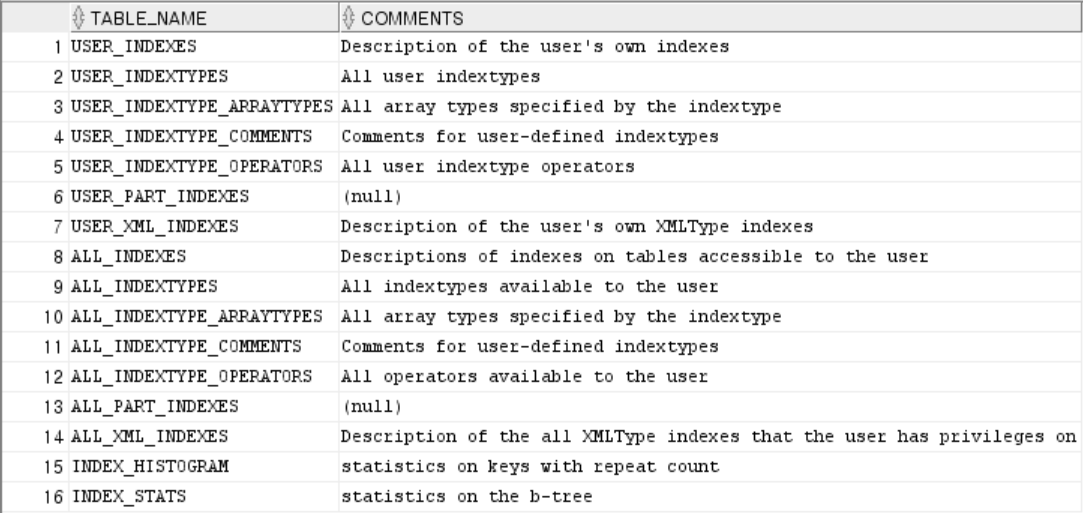
오라클 딕셔너리 접두어
- ALL_* : 현재 오라클에 접속한 사용자가 접근 가능한 모든 정보에 대한 딕셔너리
- USER_* : 현재 오라클에 접속한 사용자가 소유하고 있는 모든 정보에 대한 딕셔너리
- DBA_* : 관리자 계정으로 접속한 사용자가 조회 가능한 모든 정보에 대한 딕셔너리
- V$* : Dynamic Performance View라고도 하며, DBA의 모니터링에 많이 이용되는 딕셔너리
접속한 계정이 관리자 계정인지 사용자 계정인지에 따라 조회 가능한 딕셔너리가 구분된다.
'STUDY > DB' 카테고리의 다른 글
Index Scan (0) 2023.04.12 개발자를 위한 인덱스 생성과 SQL 작성 노하우 : 22-24 (0) 2022.08.30 개발자를 위한 인덱스 생성과 SQL작성 노하우 : 15-17 (0) 2022.08.10 개발자를 위한 인덱스 생성과 SQL 작성 노하우 : 12-14 (0) 2022.08.01 개발자를 위한 인덱스 생성과 SQL작성 노하우 : 9-11 (0) 2022.07.25