-
Join
두 개 이상의 테이블에서 조인 컬럼에 일치하는 행을 찾아서 연결하는 것으로, 대부분 SQL 쿼리에서 사용되며, 데이터베이스의 논리적 연산 중 하나이다.
Driving Table
조인을 할 때 기준이 되는 테이블로, 조인 컬럼에 대해 인덱스를 가지고 있는 경우에 선택된다. 인덱스를 가진 테이블을 기준으로 조인을 수행하면, 조인 컬럼을 이용해 빠르게 해당 행을 찾을 수 있다.
Driven Table
드라이빙 테이블에서 조인 컬럼과 일치하는 모든 행을 찾아서 조인하는 테이블
Join 종류
1. Nested Loop Join(순차적 루프에 의한 접근 방식)
- 가장 기본적인 Join 방식으로, 두 개의 테이블 중 하나를 기준으로 하나씩 순차적으로 읽어들이면서 다른 테이블과 조인하는 방식
- 순차적으로 처리된다.
- 선행 테이블과 일치하는 값을 후행 테이블에서 찾아야 하므로 후행 테이블의 해당 열에 인덱스가 필요하다.
- 메모리 사용량은 가장 적다.
- 랜덤 엑세스 방식으로 데이터를 읽음
- 두 테이블의 크기는 성능과 관련이 없다.


- 작동 방식
- 조인할 두 개의 테이블 중 하나를 기준으로 선택(보통은 인덱스를 가진 테이블을 기준으로 선택)
- 기준 테이블을 스캔하면서 조인 컬럼의 값을 가져옴
- 가져온 조인 컬럼 값을 이용하여 다른 테이블을 스캔하여 일치하는 값을 찾음
- 일치하는 값이 존재하면, 두 테이블의 행을 조인하여 결과를 반환
- 2-4 단계를 반복하여 모든 조인 결과를 반환
- 작은 테이블에 대해서는 높은 성능을 보이지만, 대용량 테이블에 대해서는 처리 속도가 느리다.
- 조인 컬럼이 인덱스로 지정된 경우 효율적
- 조인 컬럼의 카디널리티가 높은 경우에는 비효율적
[예시]

처리 순서
- 고객 테이블에서 이름이 '홍길동'인 고객을 구한다(선행 테이블 결정).
- '홍길동' 고객의 수만큼 순차적으로 주문 테이블 고객번호 컬럼으로 접근한다(순차적 접근).
- 주문 테이블에서 주문일자가 '20220101'인 정보만 필터한다.
2. Sort Merge Join(정렬을 통한 접근 방식)
- 두 개의 테이블을 정렬한 후, 정렬된 결과를 조인하는 방식
- 조인 컬럼에 대한 인덱스가 없어도 처리가 가능
- 대용량 테이블이나, 조인 컬럼의 카디널리티가 높은 경우에도 높은 성능을 보임
- 두 테이블을 정렬해야 하기 때문에, 높은 자원 사용량을 가짐
- 정렬이 필요하므로 처리 속도가 느릴 수 있음


- 작동 방식
- 조인할 두 개의 테이블을 각각 조인 컬럼을 기준으로 정렬
- 정렬된 두 테이블을 순차적으로 비교하면서 일치하는 행을 찾아 조인
- 2단계를 반복하여 모든 조인 결과를 반환
[예시]
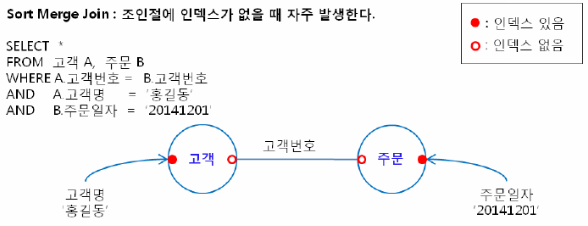
처리 순서
- 고객 테이블에서 이름이 '홍길동'인 고개글 구한 후 고객번호 순으로 정렬한다(SORT).
- 주문 테이블에서 주문일자가 '20220101'인 주문을 구한 후 고객번호 순으로 정렬한다(SORT).
- 정렬된 고객정보와 정렬된 주문정보를 고객번호로 조인한다(MERGE).
3. Hash Join(해시 함수를 이용한 접근 방식)
- 두 개의 테이블 중 하나를 기준으로 해시 함수를 사용하여 해시 테이블을 만들고, 다른 테이블에서는 같은 해시 함수를 사용하여 조인 컬럼의 값을 해싱한 후, 해시 테이블에서 일치하는 값을 찾아서 조인하는 방식
- 해시 함수를 이용하여 조인을 수행하기 때문에 "="로 수행하는 조인에서만 사용 가능하다.
- 해시 함수를 이용하여 조인을 수행하기 때문에, 인덱스를 생성할 필요가 없다.
- 해시 함수를 사용하여 메모리를 효율적으로 사용하기 때문에, 대용량의 테이블에서 빠른 처리 속도를 보임
- 해시 테이블 구성 작업에 부하가 많이 발생하기 때문에, 작은 테이블에 먼저 접근하는 것이 성능 면에서 효율적
- 해시 함수를 계산하는 데 걸리는 시간이 오래 걸리기 때문에 초기 설정 시간이 길어질 수 있고, 해시 충돌이 발생할 경우 성능이 저하될 수 있음

- 작동 방식
- 조인할 두 개의 테이블 중 하나를 선택하여 조인 컬럼을 기준으로 해시 테이블을 생성
- 선택된 테이블의 모든 행에 대해 해시 함수를 적용하여 해시 테이블에 저장(조인 컬럼과 SELECT절에서 필요로 하는 컬럼도 함께 저장)
- 나머지 테이블의 모든 행에 대해 해시 함수를 적용하여 해시 테이블에서 일치하는 값이 있는지 검색
- 해시 테이블에서 검색한 결과와 일치하는 행을 찾아서 조인
- 3-4 단계를 반복하여 모든 조인 결과를 반환
[예시]
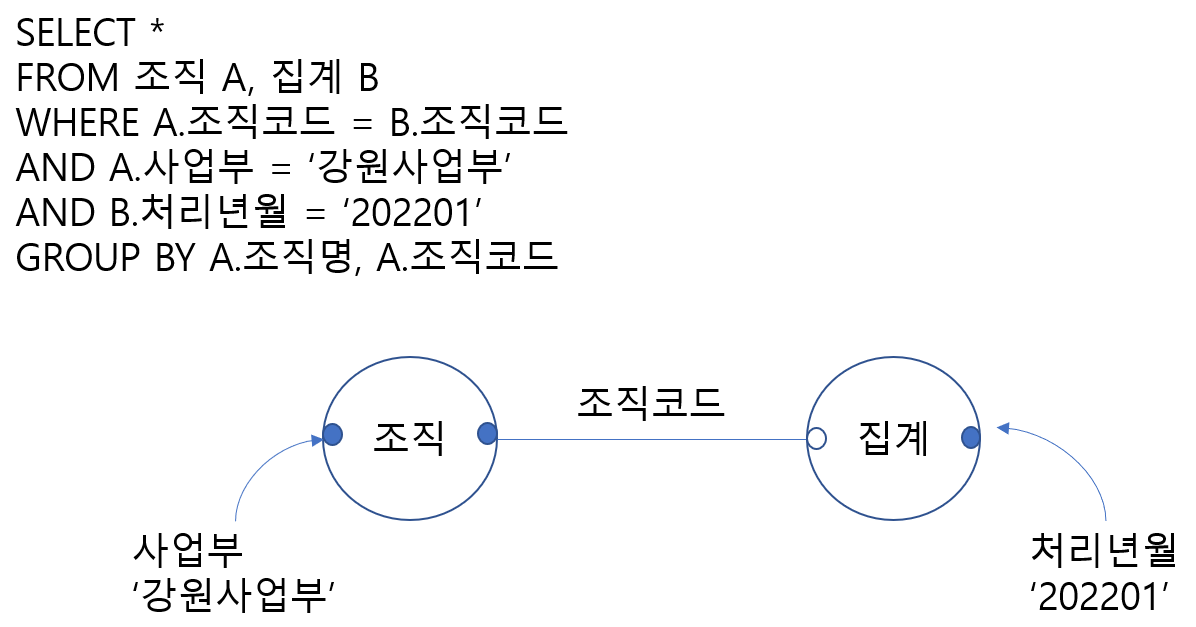
처리 순서
- 조직 테이블에서 사업부가 '강원사업부'인 조직들을 구한 후, 조인절 컬럼인 조직코드를 해시 함수로 분류한 다음, 해시 테이블을 생성한다(해시 함수를 이용해 해시 테이블 생성).
- 집계 테이블에서 처리년월이 '202201'인 자료를 구한 후, 조인절 컬럼인 조직코드를 해시 함수로 변환 후 해시 테이블로 순차적으로 접근한다(해시 함수를 통해 해시 테이블 탐색).

참고
https://velog.io/@eunhye_/SQL-%EC%A1%B0%EC%9D%B8Join-%EC%88%98%ED%96%89-%EC%9B%90%EB%A6%AC
'STUDY > DB' 카테고리의 다른 글
Isolation Level (0) 2023.04.25 실행계획 (0) 2023.04.19 Index Scan (1) 2023.04.12 개발자를 위한 인덱스 생성과 SQL 작성 노하우 : 22-24 (0) 2022.08.30 개발자를 위한 인덱스 생성과 SQL작성 노하우 : 18-20 (0) 2022.08.15